
Using Machine Learning to Detect Malicious URLs
Malicious URLs are a common and serious threat to cybersecurity. There are many ways for malicious attackers to try to cheat end user such as hacking attempts, drive-by-download, denial of service, phishing, social engineering, and many others. One of the examples we often see is the Technical Support Scam (TSS) which combines online abuse with social engineering over the phone channel. This way scammers succeed in tricking users to give them money for fake technical support service.
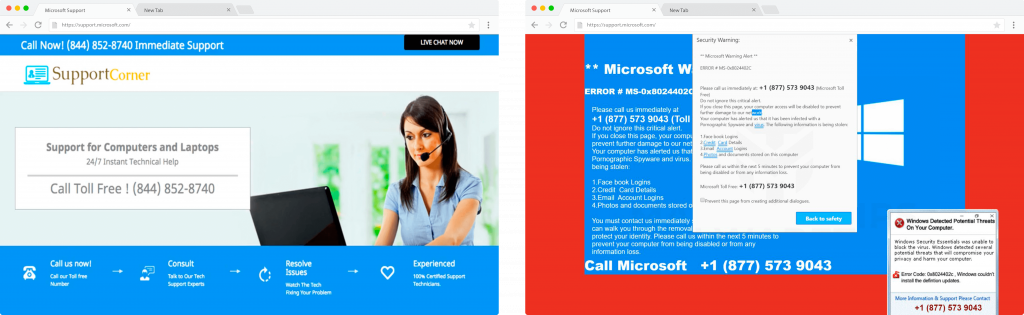
Left: Example of passive TSS page which appears to be professional. Right: Example of an aggressive TSS page which tries to provoke urgency through audio messages, continuous pop-ups, blocking browser, and warning messages.
By far the most common technique to protect users is blacklisting. This technique is extremely fast. However, it is almost impossible to maintain an up-to-date list of malicious URLs. Users may click on a malicious URL before it appears in blacklist. Therefore, most of the latest researches explore machine learning approaches to learn as much as possible about malicious URL’s behavior.
Architecture and research
Our machine learning solution uses lexical and host-based features in order to show that efficiently predicting malicious URLs can be done without analyzing page content.
Lexical features include statistical properties of the URL string, like the length of URL, special characters count, length of different parts of the URL (hostname, top-level domain, path, query), delimiter count, longest words length, different tokens count, etc. Host-based features used by our solution include IP address properties, WHOIS, and DNS information. We have implemented automated WHOIS and DNS data collection services. Also, services for the extraction of feature values from collected data have been implemented. During the implementation, we encountered certain technical issues, like preparation of large datasets and proper dataset labeling.
We have explored six binary classifiers: Logistic Regression, Support Vector Machine, Decision Tree, Random Forest, LightGBM, and Multi-layer Perceptron. Two data sets have been used for training and evaluation. The first dataset contains 210 million records – data manipulation, and model training have been done on Spark cluster using Apache Spark MLlib. The second dataset contains 2 million records and thus it was possible to use the Scikit-learn library to train the model.
Experimental results show that by combining proposed URL features and classifiers accuracy of 96 to 99% can be achieved. The best performance is achieved using LightGBM and Random Forest.
All research details with various examples can be found in the following paper https://infom.fon.bg.ac.rs/index.php/infom/article/view/2427/2359.
Production
By providing malicious URL detection as a service in reality we tried to accomplish several goals. First goal is achieving high precision with the highest possible recall. Secondly, malicious URL detection for online systems needs to accomplish predefined low response time. Also, the model has to be constantly retrained to yield a highly accurate classifier. Finally, it must be able to scale up for training the models with millions of new data records.
Next steps
Future work includes adding new features like NLP (Natural Language Processing) categories determined from URLs, bag-of-words, and n-gram representation of keywords, in order to achieve higher accuracy.

Written by
Jelena Jokić
Data Science Engineer