
Data Engineering at BravoSystems: Main Concepts
We service approximately 1.2 million users daily, which between them produce 120 to 220 million events. Our cluster is currently a bit over 870TB. Our biggest event generates around 120GB of data daily (without replication). We hit a couple of bumps on the road regarding the data organization, transformation, and analytics, but we managed to build a system which is robust enough to support this amount of data, and scalable enough so that the future bumps are not felt as hard as some of them were. In this one and the following few posts we aim to share our experiences and the approach which we found that works for us in hope that it will be useful to someone else from the community.
The real picture
The data is everywhere, but no one knows where it is.
Our infrastructure grew bit by bit over the years, and so did its complexity. Many companies experience that on their own when they grow beyond a certain point, but those that want to keep growing often have to rethink their initial infrastructure in the light of the amount of the data that they need to process daily.
Our company has many teams, all of which work on different parts of the same system, and all of them produce the data that others use. It is spread across different databases, such as MySQL for relational data, Redis for caching, MongoDB for unstructured data, Hadoop for structured big datasets, Redshift as an analytical database (currently in the process of being replaced with Druid), etc.
Different teams own their own databases, but each team requires the data that belongs to the other teams, so many custom imports/exports between the databases emerged. So every team had all the data it needed, right?
Not really.
Why? Well, let’s take a look at the overview of the infrastructure that this approach lead to:
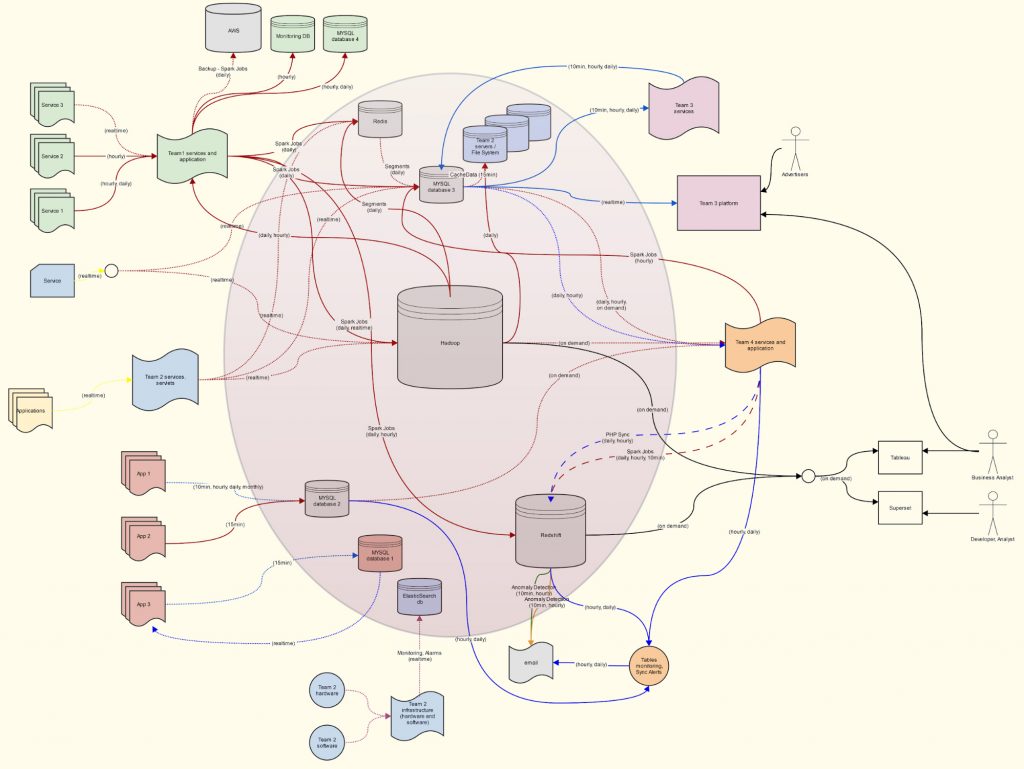
Figure 1. A scheme representing our real system about 2 years ago, only simplified by replacing the names of the services
At the center there was a heterogeneous database layer, with mixed up access rules based on the thesis “data to the people”, and around it were the services that produced that data, and other ones that were supposed to utilize it.
But, under the hood, much of the data was being duplicated between the databases. Everyone organized it in their databases based on their specific needs. There were many different methods of copying the data between the databases, which led to many discrepancies. There was practically no easy way to pinpoint the causes of those discrepancies, other than the mere hope to overcome them by introducing yet another process to copy the data “in a better way”. And that rarely worked as planned. The system just ended up being more complex.
At some point, it just got too cumbersome to maintain.
What worked for us
We can agree that the “real” picture was pretty blurry. What did we want it to be like? It would have been nice to be able to have something that can be considered as a single source of truth, to have standardized data pipelines between the different systems, to have well-defined procedures to always do similar things in a similar way, to have an easily understandable metadata tool (yeah, that’s a thing now), and to have a body of authority to oversee all of the work being done with the data.
Let’s elaborate on each of these.
Single source of truth
When we used some data, we wanted to be able to trust it. That meant that there could be no doubt if some data was missing or duplicated, or that some of it was even wrong. Colleagues from different teams had to get the same result when they performed the same aggregation of the same data.
The easiest way to achieve that was to:
- read the same data
- read from the same system
- use the same tool
In order to read the same data, they both had to be able to access its source and there had to be only one source, aka the single source of truth. It turned out that the tool can even differ if the first two points are fulfilled.
Tools that we are using: Kafka, Kafka Connectors, Debezium
Standardized data pipelines
Since the data cannot just appear out of thin air, it must be somehow ingested into the system. Since we were looking to create a single point of truth, and the data comes in in many forms and shapes, we figured that there should be an “adapter” which would adapt the incoming data to the data standards used in the system.
Since everyone should be able to trust the single source of truth, the responsibility of adapting the data falls on the shoulders of whoever creates it. That means that each team bears the responsibility to do that with their data.
This is where one of the problems arises: everyone has their way of doing it. In order to solve that problem, the standardized way to adapt the data had to be created. Also, since the data was being transferred from the “adapters” into the system, transformed inside the system for specific needs, and also transferred out of the system, the standardized ways to transfer the data also had to be defined. Today, that is what our data pipelines do.
Tools that we are using: Avro, Schema Registry, Jenkins
Doing similar things in a similar way
When we took a step back from the system and tried to note all the different things that were being done with the data, we noticed that there were only so many. The data was being cleaned, it was being enriched with other data, aggregated, presented, and finally stored for the analysts and everyone else to use.
If we know that the set of operations performed with the data is finite, why should we have an infinite number of ways to perform them? We wanted to do similar things in a similar way, and for everyone’s sake, document them. That meant introducing the tools and procedures for frequent operations. As far as the documentation goes, a simple Confluence document describing the procedure works just fine.
Tools that we are using: Schema Pipeline for Avro schemas
A usable metadata tool
Just because we are now doing similar things with the data in a similar way through the standardized data pipelines, and we store it all in a single source of truth, it does not mean that everyone knows everything that is in there and where it came from. The data is still being ingested, transformed, enriched, disassembled, used, and re-used. It is all done in a similar way, but times and times over.
If we expect someone to use the data, that someone must first be aware that it exists. Luckily, just as there are now tools for doing everything else described above, there are also tools which can be attached to every step of the process, and later lay out everything in a human-readable way. We will go deeper into how we implemented this in one of the future posts.
Tools that we are using: Apache Atlas, Confluence
A body of authority
This is a well-known concept. For two parties to be able to endeavor in solving a particular problem and feel protected whilst doing it, there must be a third party that represents a body of authority to whom both parties trust.
In order to achieve that in the light of creating a reliable data system, it seemed as a good idea to create a dedicated data engineering team that oversees the data needs of all other teams, but takes no part in the domain-specific responsibilities of those teams. Its purpose is to gather all the requirements regarding the data from other teams, and then develop and maintain all of the elements mentioned earlier. And, of course, to provide assistance to anyone that requires it in following the defined procedures.
Conclusion
Our system is now designed in a way that follows all of these concepts, and it looks something like this:
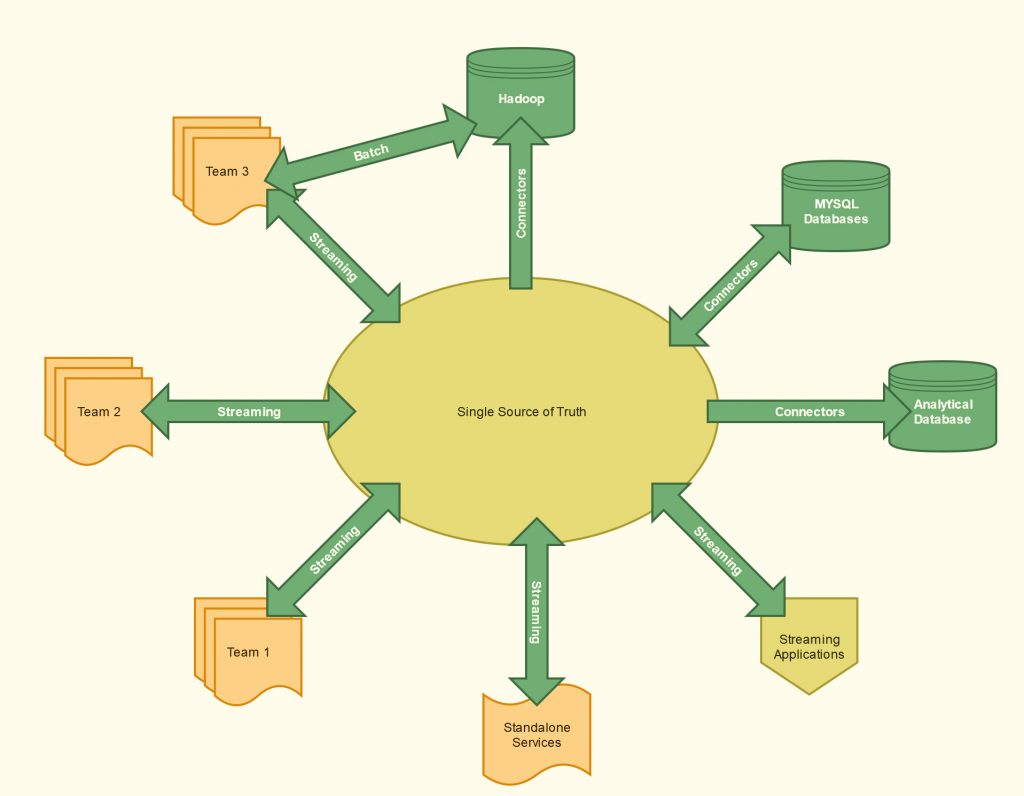
Figure 2. Abstraction of our current infrastructure
Truth be told, this image is on a higher level of abstraction than the first image representing the old system, but it does represent clearly enough that every part of the system now communicates with the single source of truth, and everyone trusts it based on the knowledge that others are communicating with it in the same way.
In the following few blog posts we will dive deeper into every concept mentioned earlier, and try to explain how we implemented them and why they work for us.

Written by
Dragan Živković
Data Engineer