
Bravo Technology stack
Historically, our teams were organized as separate products, each with its own technology stack, although the stacks were very similar for some teams. Now we are unifying our platforms, tools, and languages so that we can share knowledge and reuse services between teams in a better way.
Below is a list of our technology stack by each development area.
Infrastructure and Data
BravoSystems uses cloud and bare-metal servers across two data centers. For the cloud deployments, we use Amazon Web Services and it’s mostly used for new and experimental projects. Our legacy and stable projects are deployed to our datacenters. Infrastructure in our datacenters is provisioned through a mix of Ansible scripts and custom tools. We also have a Kubernetes cluster which is used in some of our product teams. For infrastructure monitoring, we use Nagios and Zabbix.

Figure 1. Part of our tech stack
We also built a Platform for abstracting away infrastructure from product teams. This was an upgrade from the simple Kubernetes cluster which we already had in production. We are planning to migrate legacy products alongside all new ones that are already there.
The Platform is managed through Terraform, Ansible, and Helmfile, and the heart of the platform is Kubernetes. Deployed services are packaged using Docker and Helm. On the ingress side, we use envoy as a front proxy for Kubernetes. For the storage provider, we use Portworx – cloud-native storage and data management platform. The Platform also provides monitoring and centralized logging based on Prometheus, Loki, and Grafana.
The important part is also CI/CD solution which relies on all the above. With our solution, we minimize efforts to have a fully functional CI/CD solution for any team.
Since we are ingesting terabytes of data daily, we needed to set up proper data infrastructure to be able to efficiently use that data. For distributed storage, we use Hadoop cluster. In addition, we backup everything on AWS S3 and Glacier. Analytical data is currently stored in Amazon RedShift or Clickhouse and we are currently migrating to Druid. For metadata management and governance we use Apache Atlas.
For ETL orchestration and management we use Apache Airflow with a combination of our internal tools. For data streaming, we use Kafka. ETLs are mostly written in Python or Java.
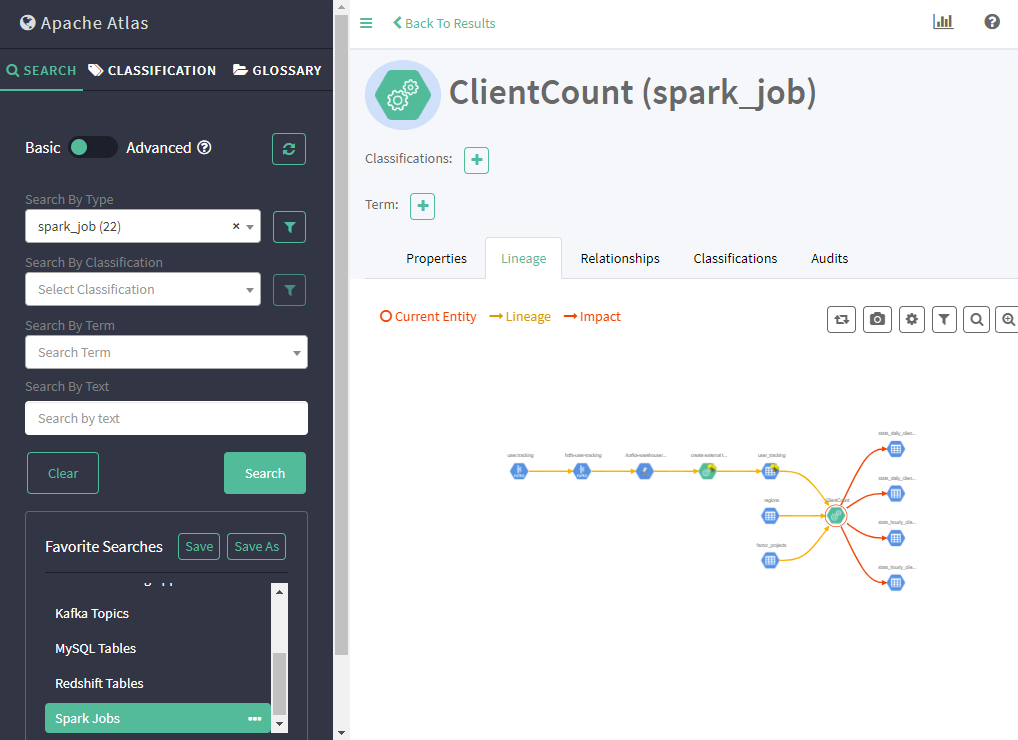
Figure 2. Apache Atlas showing lineage of one of our Spark ETL jobs.
Backend
Our primary backend language is Java because of its performance and extensive support for external ecosystems like Apache, which we use a lot (Hadoop, Spark, Kafka..).
Other languages we use are PHP and NodeJs. We use PHP in our legacy products. NodeJs is mostly used for new and experimental projects because of a faster learning curve for junior developers, so we can take those projects to market as soon as possible. Our teams use MySQL and MongoDB as the production database. Where caching is needed, we use Redis.
For the majority of tracking and logging, we use Kafka, which stores data into Hadoop using various streaming applications.
Several teams are using ELK (Elasticsearch, Logstash, and Kibana) for application monitoring.
Usually, alerting mechanisms are set up per team i.e. the team that builds a service is responsible for monitoring that service.
Frontend
Our primary frontend language is Javascript, and we build our projects with ExtJs, VueJs, and ReactJs. For testing, we mostly use Jest for the unit and Testcafe for functional testing. We have also built our internal test tool based on Selenium and Sikuli called Hodor for end-to-end tests which enables us to test browser extensions. We have used Cucumber to write acceptance tests in one of our products.
As for web servers, we use Apache HTTP and nginx.
Figure 3. Cucumber reports showing test executions
Development and Deployment
Some of our legacy products are still deployed on bare-metal servers, which are managed by a centralized admin team. Also, in some teams where we use the on-prem Kubernetes cluster or AWS, that team manages deployment configuration themselves. Our in-house Platform made deployment very simple.
For Continuous Integration and Deployment, we use Jenkins to run our pipelines. For artifacts management, we use Artifactory, where we store built release candidates, libraries, and various other artifacts. Artifactory also serves as a Docker registry and a maven repository. Code collaboration is done using Bitbucket, and we use Jira as a bug/issue tracking tool. We use Vagrant for managing some development environments and Docker for packaging most of our deployments.
Teams are mostly using Feature Branching as git workflow although we also use trunk-based development and feature toggling to enable experimentation and combination of work-in-progress and completed features.
DataScience: Machine Learning and Analytics
Our products have various KPIs which we regularly monitor. KPI reports are mostly built on Tableau and Zeppelin. We also use Metabase for various reporting. The analytics team built an anomaly detection tool called Sherlock which uses prediction models to check our most important KPIs.
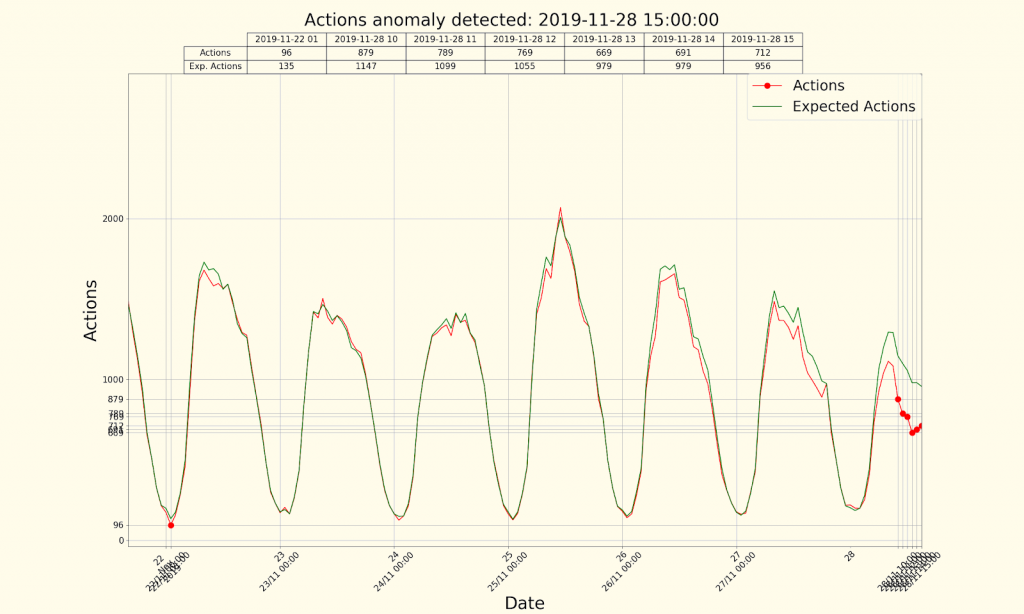
Figure 4. Anomaly detection tool Sherlock finds anomaly during Thanksgiving day.
Alerts trigger email and Slack notifications that are sent to all relevant people. DataScience teams use Jupyter which is connected to our data platform. On top of our Hadoop cluster, we use Apache Spark and Hive.
We use various machine learning algorithms in our products, like LightGBM and XGBoost, and various unsupervised ML algorithms. Besides that, we also work on building our NLP (Natural Language Processing) solutions.
Next steps
Our tech stack is constantly evolving, some tools stop being used, new ones are added to the list. We will try to keep you posted on any new tool we found useful in building our products. This article is just a high-level overview or our stack and in the following articles, we will try to give more insights into these development areas, like Data, Infrastructure, Machine Learning, etc… In the meantime, if you would like to join our team and explore these technologies, go to “Be Bravo” section and apply for open positions.

Written by
Dejan Cvijanović
Head of Technology