
Back to on-premises: Migrating from Cloud to Data Center and handling millions requests per second
Why?
In the age of cloud, why do we continue to build and invest into data center infrastructure? Answer to this question is fairly simple if you have knowledge and manpower to implement everything by yourself. By doing this we significantly reduce costs, increase performance and security and in the end we do have an ultimate control over all of our infrastructure.
While having experience with both, cloud and on-premises, we still choose on-premises as a way to go. That is the road we took in our latest project of migrating our business partner’s entire production infrastructure from cloud to bare metal servers in Data Center.
We had hundreds of instances, multiple kubernetes clusters, different databases and a six-figure monthly bill we had to take care of. It takes a lot of planning and thinking through but luckily this not our first rodeo.
Planning & Challenges
It took some time to thoroughly analyze entire cloud infrastructure and decide what hardware will be needed on-premises to satisfy current needs and leave some room for growth.
Having in mind huge growth of the company we had to be prepared for anything, so we started with designing entire solution from scratch. It implied that we have to take care of everything, including new racks in data center, internet links, direct connections with cloud providers, network equipment, power, servers and so on.
Bravo Systems Admin Team has been leading the entire project since the beginning. Besides technical part of the project we did procurement of all needed hardware. It took us some time to finish countless meetings with world’s largest vendors and internet service providers in order to get the best possible prices and conditions and we have delivered it.
However, buying such large quantities of hardware in the time of worldwide pandemic is quite a challenging task. With disrupted supply chain, huge lead times and postponed deliveries we had to put a lot of effort in keeping everything on track and ready according to schedule.
Implementation
Finally we’ve reached a moment to put our servers, routers, switches and other equipment in racks and we could start with network and servers configuration.
Almost entire infrastructure has been configured with Ansible and other automation tools. In order to efficiently configure such amount of hardware we had to make automation scripts for most of the tasks that were ahead of us.
For example, we have installed and configured dozens of Linux servers with several lines of code in just a couple of minutes. From BIOS, RAID and hardware configuration, firmware updates, OS configuration, package installation to fine-tuning is done through code.
(Installing and configuring Linux on multiple servers with Ansible and PXE)
We had to be prepared to handle huge amount of internal and external traffic so we connected all servers, routers and switches with each other with 50/100/200 Gbps links. Besides that we have multiple internet links (BGP) from world’s largest Internet Service Providers and our own ASN.
Since we are receiving significant amount (tenths of gigabits per second) of external traffic we had to make custom implementation of load balancers in order to efficiently distribute it to kubernetes clusters. We used latest and cutting edge technologies so we could be able to be on top of our game.
All that data is being stored on petabytes of storage and crunched on servers with 192 cores and up to 1 TB of RAM per server.
After weeks of extensive testing, fine-tuning and fixing various issues we were ready for migration and production.
Production
Migration from cloud to data center went without any issues and we were up and running in no time without any downtime or impact to customers. In just a couple of days we have seen huge improvements all over the place and we had enough resources to grow without any concerns.
Entire infrastructure is created to be highly available and rack aware so we can get the most of the hardware that we have and still be safe in case of failures. With this design we can lose an entire rack of servers and network equipment and we can still be up and running. Also we can easily add more hardware/racks and increase our processing power and availability.
Months after
Couple of months have passed after migration to data center, company continued to grow and incoming traffic increased multiple times.
Due to good design we are handling it without any issues and currently we are receiving more than 2M req/s (expecting 3M req/s in the next couple of months) on our custom made load balancers and kubernetes clusters behind them.
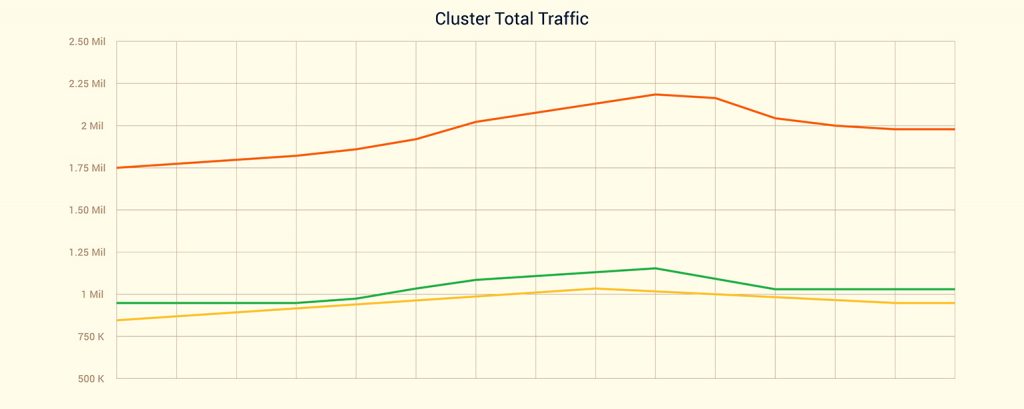
Even with significant traffic increase, there were no additional costs since everything is running on-premises which compared to running it on cloud would have caused quite the opposite.
What’s next?
Next has already come. While making huge savings with moving to on-premises we can invest in additional hardware and successfully track the company’s growth yet keeping the cost low and performance high.
New batch of servers is on the way and some of them are already being racked and stacked at this very moment.
In this never ending process we are always trying to find ways to optimize even more and to squeeze the last drop of processing power and memory, while keeping the system stable, fast and on top of all secure.
Conclusion
In the end it’s definitely easier and faster to keep clicking on cloud portals and spawn instances in a split of a second.
Is it better? – From our experience and use cases, it’s not.
It’s just too expensive in many different ways. Let’s put the money aside and think about “vendor locking”. If you go deep with using cloud provider’s proprietary services/technologies you are locking your infrastructure/business with them and moving away is usually a painful process and takes a lot of time. Having that in mind, whatever we do we make it infrastructure agnostic so we can scale wherever we want. Even in extreme cases where we need more resources right away we can scale to cloud or different data center without any issues.
This approach has proven to be the best so far, but we will see what the future holds.

Written by
Dušan Umljenović
System Engineer